Introducing OpenPCC

As AI becomes more powerful and accessible, the stakes around data privacy and protection are higher than ever. For instance, a single employee, seeking to leverage AI’s ability to read and understand a PDF, can easily upload a confidential document to an LLM and, in doing so, mistakenly expose PII or trade secrets. Worse, these private data may be stored and used to train and improve future models, eroding any data-related competitive advantages an enterprise has.
Data privacy risks are not new, but AI’s capabilities and prevalence amplify them dramatically.
These risks are no longer hypothetical:
- A 2025 survey found that in enterprise environments, 40% of files uploaded into GenAI tools contain PII or PCI data, and 45% of all employees are using GenAI tools.
- Anthropic recently began defaulting to including all user-submitted data in training. On major AI providers today, users must opt-out of data training rather than a more user-friendly opt-in.
- Meta, Grok, Anthropic, and OpenAI have all suffered leaks that exposed hundreds of thousands of very confidential chat logs to the public Internet, and search engines subsequently indexed them.
- In an extremely high-profile case, OpenAI was legally forced to retain “deleted” and “temporary” prompts and responses by a judge, violating user expectations and revealing the capability is indeed possible – the servers retain private prompt data. In this instance, two parties were at risk: the users and the operator (OpenAI) due to legal proceedings.
These risks exist in current AI environments because private prompts and responses are available alongside user identifiers that can be linked to names, email addresses, and other personal information. In any system where user prompts and identities are accessible, there is an incentive – and eventual legal compulsion – to log and retain that information. Even when AI providers intend to use stored data only for analytics, customer support, debugging, or training, the only true way to guarantee that prompts and personal data remain - now and in the future - is to ensure they’re never accessible to anyone in the first place. If stored, user prompts and identities can be exposed in a security breach by insiders, other users, or even nation-state actors.
The Trust Problem
Beneath data privacy concerns lies a fundamental challenge of developing trust among the following parties:
- Data owners (user) - do not want to share private or proprietary data but do not have the ability to run the best (proprietary) models themselves nor have the budget to afford AI hardware.
- Model owners - do not want to leak or disclose proprietary model weights, may want to use additional proprietary data for training, and must ensure models are used safely.
- Software operators - may integrate model weights with an inference engine running on cloud hardware but are really intermediaries assuming all risk.
- Hardware providers - lease access to compute resources, are responsible for up-to-date hardware, and control physical access to hardware.
Each party has varying degrees of trust in the others, and any breach by one compromises them all. Note that their incentives are misaligned, but they will all feel the consequences of a data breach!
Approaches to AI data privacy often rely on shifting trust among the parties mentioned above. But so far, these methods have consistently fallen short. Contractual promises will be broken, redaction and obfuscation are incomplete and prone to leaks, and self-hosting/on-premise is prohibitively expensive given the high cost of AI hardware and the power to run them. Even then, proprietary models often remain inaccessible. The only approach that truly addresses all of these challenges is a combination of full anonymization and full encryption. To guarantee user prompts and responses cannot be subpoenaed, stolen, used for training, or leaked, they must not be stored at all. To guarantee users and their data cannot be identified or targeted, they must remain anonymous.
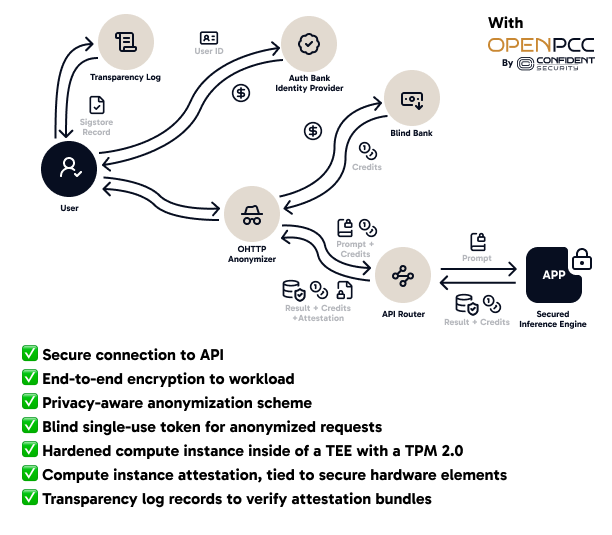
Today, we’re introducing OpenPCC, a security and privacy standard for providing provably-confidential cloud compute to clients. Designed for multi-modal AI models and other inference engines, OpenPCC describes a system for inference on private or otherwise sensitive data such that inputs and outputs remain completely hidden from all participants. The standard also specifies an anonymization scheme to protect the privacy of customers from side-channel leaks, including API timing, payment side channels, and metadata analysis. Our whitepaper fully describes this standard. And, finally, there’s a fully-featured Apache 2.0 open-source implementation written in Go. I invite you to check it out by either reviewing the whitepaper, running it all locally, or trying it on our platform. Our waitlist is open!
Thank you to the whole team who have put this together and are making AI more private and secure. More to follow!
Figure 1. Legacy Inference Providers
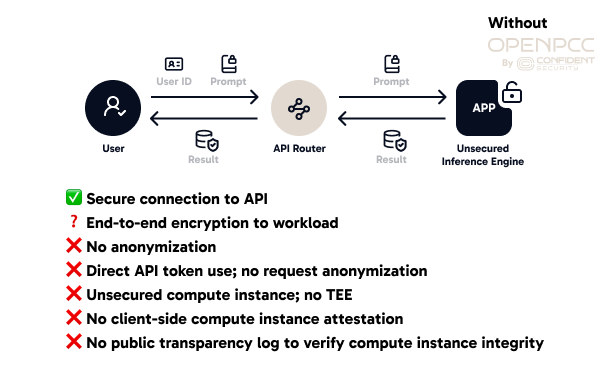
Figure 2. OpenPCC Inference Providers